| Situation | Zielgrösse | Test | R-Funktion |
|---|---|---|---|
| Anteil vs. Sollwert | Anteil / Rate | Binomialtest | binom.test(x, n, p = …) |
| Mittelwert vs. Sollwert, σ bekannt | Mittelwert | Gauß-Test (z-Test) | pnorm() / qnorm() |
| Mittelwert vs. Sollwert, σ unbekannt | Mittelwert | Einstichproben-t-Test | t.test(x, mu = …) |
| Gleiche Einheiten vor/nach | Mitteldifferenz | Verbundener t-Test | t.test(x, y, paired = TRUE) |
| Zwei unabh. Gruppen, Mittelwerte | Mittelwert | Zweistichproben-t-Test (Welch) | t.test(x, y, var.equal = FALSE) |
| Zwei unabh. Gruppen, Anteile | Anteilsdifferenz | Zweistichproben-Anteilstest | prop.test(c(x1,x2), c(n1,n2)) |
TippLernziele
Lernziele
Nach diesen Übungen …
- kann ich für eine gegebene Praxissituation eigenständig eine statistisch korrekte Null- und Alternativhypothese formulieren – mit der richtigen Testrichtung.
- bin ich in der Lage, alle sieben Standardtests (Binomialtest, Gauß-Test, Einstichproben-t-Test, verbundener t-Test, Welch-t-Test, Zweistichproben-Anteilstest, χ²-Test) situationsgerecht auszuwählen und zu begründen.
- kann ich die Prüfstatistik analytisch berechnen, mit dem kritischen Wert vergleichen und eine begründete Testentscheidung treffen.
- bin ich in der Lage, p-Wert, Konfidenzintervall und Testentscheidung korrekt zu interpretieren und von inhaltlicher Signifikanz abzugrenzen.
- kann ich Fehler 1. und 2. Art sowie statistische Power im Praxiskontext benennen.
HinweisHinweise zur Bearbeitung
Bearbeiten Sie jede Aufgabe vollständig, bevor Sie die Musterlösung aufklappen. Die analytische Lösung zeigt den vollständigen Rechenweg; die R-Lösung dient zur Verifikation und Ergänzung.
Diagnose-Raster
Aufgabe 1: CI/CD-Fehlerquote (Binomialtest)
Ein Fintech-Unternehmen setzt ein neues CI/CD-Framework (Contineous Integration/Contineous Deployment) ein. Das Ops-Team behauptet, die Deployment-Fehlerquote liege unter der kritischen Marke von 5 %. In den letzten zwei Wochen wurden 320 Deployments protokolliert, davon schlugen 21 fehl. Verwenden Sie \(\alpha = 0{,}05\).
- Formulieren Sie \(H_0\) und \(H_1\) in Worten und in mathematischer Notation. Begründen Sie die Testrichtung.
- Warum ist hier ein Binomialtest und kein t-Test angebracht? Prüfen Sie die Faustregel \(n \cdot p_0 \geq 5\) und \(n \cdot (1-p_0) \geq 5\).
- Berechnen Sie die Prüfstatistik der Normalapproximation \(z = (\hat{p} - p_0) \,/\, \sqrt{p_0(1-p_0)/n}\) und treffen Sie eine Testentscheidung. Kritischer Wert: \(z_{0{,}05} = -1{,}645\).
- Führen Sie den exakten Binomialtest mit
binom.test()durch und vergleichen Sie das Ergebnis mit (c).
- Erläutern Sie: (1) Den Unterschied zwischen «\(H_0\) nicht ablehnen» und «\(H_0\) beweisen». (2) Was wäre je ein Fehler 1. und 2. Art in diesem Kontext? (3) Formulieren Sie das Ergebnis in einem Satz ohne statistische Fachbegriffe.
TippAnalytische Lösung anzeigen
a) Hypothesen
Die Behauptung «Fehlerquote liegt unter 5 %» soll bewiesen werden → \(H_1\):
\[H_0: p \geq 0{,}05 \qquad \text{vs.} \qquad H_1: p < 0{,}05 \quad \text{(linksseitig)}\]
b) Testwahl und Faustregel
Die Zielgrösse ist ein Anteil → Binomialtest. Faustregel: \(n \cdot p_0 = 320 \cdot 0{,}05 = 16 \geq 5\) ✓ und \(n \cdot (1-p_0) = 304 \geq 5\) ✓ → Normalapproximation zulässig.
c) Analytische Berechnung
Gegeben: \(\hat{p} = 21/320 = 0{,}065625\), \(p_0 = 0{,}05\), \(n = 320\).
\[z = \frac{0{,}065625 - 0{,}05}{\sqrt{0{,}05 \cdot 0{,}95 \,/\, 320}} = \frac{0{,}015625}{0{,}01218} \approx +1{,}28\]
Da \(z = +1{,}28 > z_{0{,}05} = -1{,}645\): \(H_0\) wird nicht abgelehnt.
d) R-Ergebnis
Exakter Binomialtest: \(p = 0{,}9173 \gg 0{,}05\) → \(H_0\) nicht abgelehnt. Normalapproximation und exakter Test stimmen überein.
e) Verständnis und Interpretation
- Nicht abgelehnt ≠ bewiesen: «\(H_0\) nicht ablehnen» bedeutet lediglich, dass die Daten nicht ausreichen, um \(H_0\) zu verwerfen. Mit \(\hat{p} = 6{,}6\,\%\) weisen die Daten sogar in die entgegengesetzte Richtung.
- Fehler 1. Art: Wir erklären die Fehlerquote als unter 5 %, obwohl sie es nicht ist → falsches Zertifikat. Fehler 2. Art: Das System erfüllt die SLA-Grenze tatsächlich, wir erkennen es nicht → verpasste Freigabe.
- Managementsatz: Die verfügbaren Daten liefern keinen Beleg dafür, dass die Fehlerquote unter 5 % liegt – mit gemessenen 6,6 % ist das SLA-Ziel aktuell nicht nachweislich erfüllt.
Häufige Fehler: \(H_0\) und \(H_1\) vertauscht; Testrichtung rechtsseitig statt linksseitig; t-Test statt Binomialtest.
TippLösung mit R anzeigen
Code
n <- 320
x <- 21
p_0 <- 0.05
# Normalapproximation (manuell)
p_hat <- x / n
z_beob <- (p_hat - p_0) / sqrt(p_0 * (1 - p_0) / n)
z_krit <- qnorm(0.05) # linksseitiger Test
cat("p̂ =", round(p_hat, 5), "\n")p̂ = 0.06563 Code
cat("z =", round(z_beob, 4), "(Normalapproximation)\n")z = 1.2825 (Normalapproximation)Code
cat("z* =", round(z_krit, 4), "\n")z* = -1.6449 Code
cat("Entscheidung:", ifelse(z_beob < z_krit, "H0 ablehnen", "H0 nicht ablehnen"), "\n\n")Entscheidung: H0 nicht ablehnen Code
# Exakter Binomialtest
ergebnis <- binom.test(x, n, p = p_0, alternative = "less")
cat("Exakter Binomialtest:\n")Exakter Binomialtest:Code
cat(" p-Wert =", round(ergebnis$p.value, 4), "\n") p-Wert = 0.9162 Code
cat(" 95%-KI: [", round(ergebnis$conf.int[1]*100, 2),
"%, ", round(ergebnis$conf.int[2]*100, 2), "%]\n", sep = "") 95%-KI: [0%, 9.31%]Aufgabe 2: API-Antwortzeiten nach CDN-Umstellung (Gauß-Test)
Ein SaaS-Unternehmen betreibt sein API-Monitoring seit drei Jahren. Aus über 50 000 historischen Messungen ist die Standardabweichung der Antwortzeiten mit \(\sigma = 40\) ms bekannt. Der historische Mittelwert lag bei \(\mu_0 = 200\) ms. Nach einer CDN-Konfigurationsänderung (Contineous Delivery Network) werden \(n = 100\) Antwortzeiten gemessen; der Stichprobenmittelwert beträgt \(\bar{x} = 192\) ms. Verwenden Sie \(\alpha = 0{,}05\).
- Formulieren Sie \(H_0\) und \(H_1\). Begründen Sie, warum ein zweiseitiger Test angebracht ist.
- Warum kann hier der Gauß-Test statt des t-Tests verwendet werden? Welche Bedingung macht das möglich?
- Berechnen Sie den Standardfehler \(\sigma_{\bar{X}} = \sigma/\sqrt{n}\) und die Gauß-Prüfstatistik \(z = (\bar{x} - \mu_0) / \sigma_{\bar{X}}\). Kritische Werte: \(\pm z_{0{,}025} = \pm 1{,}960\). Berechnen Sie den p-Wert \(p = 2 \cdot \Phi(z)\) für \(z < 0\).
- Berechnen Sie p-Wert und 95-%-KI in R. Führen Sie zum Vergleich
t.test()durch und notieren Sie den Unterschied in den kritischen Werten.
- Erläutern Sie: (1) Warum haben Gauß-Test und t-Test bei \(n = 100\) fast identische kritische Werte? (2) Warum führt ein KI, das \(\mu_0\) ausschliesst, zur gleichen Entscheidung wie \(p < \alpha\)? (3) Ist eine Reduktion um 8 ms auch inhaltlich bedeutsam?
TippAnalytische Lösung anzeigen
a) Hypothesen
«Hat sich der Wert verändert» gibt keine Richtung vor → zweiseitig:
\[H_0: \mu = 200\,\text{ms} \qquad \text{vs.} \qquad H_1: \mu \neq 200\,\text{ms}\]
b) Testwahl
\(\sigma = 40\) ms ist aus über 50 000 Messungen bekannt → Prüfstatistik unter \(H_0\) exakt standardnormalverteilt → Gauß-Test. Beim t-Test würde \(\sigma\) durch \(s\) aus der aktuellen Stichprobe geschätzt, was unnötige Unsicherheit einführt.
c) Analytische Berechnung
Gegeben: \(\sigma = 40\), \(n = 100\), \(\bar{x} = 192\), \(\mu_0 = 200\).
\[\sigma_{\bar{X}} = \frac{40}{\sqrt{100}} = 4\,\text{ms}\]
\[z = \frac{192 - 200}{4} = \frac{-8}{4} = -2{,}00\]
Da \(|z| = 2{,}00 > 1{,}960\): \(H_0\) wird abgelehnt.
p-Wert: \(p = 2 \cdot \Phi(-2{,}00) = 2 \cdot 0{,}0228 = 0{,}0456\).
95-%-KI: \(192 \pm 1{,}960 \cdot 4 = [184{,}2;\; 199{,}8]\) ms. Der Wert \(\mu_0 = 200\) ms liegt ausserhalb → konsistent.
d) R-Ergebnis
\(p = 0{,}0456 < 0{,}05\) → \(H_0\) ablehnen. t-kritischer Wert bei \(df = 99\): \(\pm 1{,}984\) (vs. \(\pm 1{,}960\) beim Gauß-Test).
e) Verständnis und Interpretation
- Gauß vs. t bei grossem \(n\): Der t-Test schätzt \(\sigma\) durch \(s\); die dadurch entstehende Unsicherheit bewirkt schwerere Ränder der t-Verteilung. Mit \(n = 100\) gilt \(s \approx \sigma\) und \(t_{99} \approx N(0,1)\): Differenz der kritischen Werte beträgt nur 0,024 – vernachlässigbar.
- Äquivalenz KI und Test: Das \((1-\alpha)\)-KI enthält genau jene \(\mu_0\)-Werte, für die \(H_0\) bei diesem \(\alpha\) nicht abgelehnt werden würde. Beide Aussagen sind zwei Darstellungen derselben Entscheidung.
- Inhaltliche Bedeutsamkeit: 8 ms sind statistisch signifikant (wegen \(n = 100\)). Ob sie praktisch relevant sind, hängt vom SLA und der Nutzerwahrnehmung ab – darüber sagt der p-Wert nichts.
Häufige Fehler: Einseitiger Test obwohl «verändert»; t-Test trotz bekanntem \(\sigma\); p-Wert als Wahrscheinlichkeit von \(H_0\) fehlinterpretiert.
TippLösung mit R anzeigen
Code
sigma <- 40
mu_0 <- 200
n <- 100
x_bar <- 192
# Gauß-Test manuell
se <- sigma / sqrt(n)
z <- (x_bar - mu_0) / se
p_val <- 2 * pnorm(abs(z), lower.tail = FALSE)
z_krit <- qnorm(0.975)
ki <- c(x_bar - z_krit * se, x_bar + z_krit * se)
cat("Standardfehler σ/√n:", se, "ms\n")Standardfehler σ/√n: 4 msCode
cat("Prüfstatistik z: ", round(z, 4), "\n")Prüfstatistik z: -2 Code
cat("Kritischer Wert ± ", round(z_krit, 4), "\n")Kritischer Wert ± 1.96 Code
cat("p-Wert: ", round(p_val, 4), "\n")p-Wert: 0.0455 Code
cat("95%-KI: [", round(ki[1], 2), ";", round(ki[2], 2), "] ms\n\n")95%-KI: [ 184.16 ; 199.84 ] msCode
# Vergleich: t-Test (schätzt σ aus Daten – hypothetisch, da wir keine Rohdaten haben)
cat("t-kritischer Wert bei df = 99:", round(qt(0.975, df = 99), 4), "\n")t-kritischer Wert bei df = 99: 1.9842 Aufgabe 3: Sprint-Velocity (Einstichproben-t-Test)
Ein Scrum-Master behauptet: «Unsere durchschnittliche Sprint-Velocity liegt über dem Unternehmens-Benchmark von 42 Story Points.» Die letzten 9 Sprints liefern die Werte: 38, 45, 47, 41, 50, 43, 39, 46, 44. Verwenden Sie \(\alpha = 0{,}05\).
- Formulieren Sie \(H_0\) und \(H_1\) mit \(\mu\). Begründen Sie die Testrichtung.
- Warum ist hier der t-Test und nicht der Gauß-Test zu verwenden? Welche Voraussetzung ist bei \(n = 9\) besonders kritisch?
- Berechnen Sie \(\bar{x}\) und \(s\) aus den Daten. Bestimmen Sie die Teststatistik \(t = (\bar{x} - \mu_0) / (s/\sqrt{n})\) mit \(df = 8\). Kritischer Wert (rechtsseitig): \(t_{8;\,0{,}05} = 1{,}860\).
- Führen Sie
t.test()mitalternative = "greater"durch. Erstellen Sie einen QQ-Plot (und optional einen Shapiro-Wilk-Test).
- Erläutern Sie:
- «Nicht signifikant» bedeutet nicht «kein Effekt» – formulieren Sie eine präzise Aussage.
- Berechnen Sie die Power für einen echten Effekt von 2 SP und das benötigte \(n\) für 80 % Power.
- Was wäre ein Fehler 2. Art, und welche Konsequenz könnte er haben?
TippAnalytische Lösung anzeigen
a) Hypothesen
«Velocity liegt über 42» ist die Behauptung → \(H_1\):
\[H_0: \mu \leq 42 \qquad \text{vs.} \qquad H_1: \mu > 42 \quad \text{(rechtsseitig)}\]
b) Testwahl
\(\sigma\) ist unbekannt → muss durch \(s\) geschätzt werden → Einstichproben-t-Test. Bei \(n = 9\) ist die Normalverteilungsannahme besonders kritisch: QQ-Plot und Shapiro-Wilk sind obligatorisch.
c) Analytische Berechnung
\[\bar{x} = \frac{38+45+47+41+50+43+39+46+44}{9} = \frac{393}{9} = 43{,}\overline{6}\]
\[s = \sqrt{\frac{\sum(x_i - \bar{x})^2}{8}} = \sqrt{\frac{120}{8}} = \sqrt{15} \approx 3{,}873\]
\[t = \frac{43{,}\overline{6} - 42}{3{,}873 / \sqrt{9}} = \frac{1{,}\overline{6}}{1{,}291} \approx 1{,}291\]
Da \(t = 1{,}291 < t_{8;\,0{,}05} = 1{,}860\): \(H_0\) wird nicht abgelehnt.
Einseitiges 95-%-KI: \([43{,}\overline{6} - 1{,}860 \cdot 1{,}291;\, +\infty) = [41{,}3;\, +\infty)\) → enthält 42.
d) R-Ergebnis
\(p \approx 0{,}116 > 0{,}05\) → \(H_0\) nicht abgelehnt. Shapiro-Wilk \(p > 0{,}05\), QQ-Plot unauffällig → Normalverteilungsannahme plausibel.
e) Verständnis und Interpretation
- Präzise Aussage: «Die Stichprobe liefert keine ausreichende Evidenz zum Niveau 5 % dafür, dass die mittlere Velocity den Benchmark überschreitet.» – nicht: «Die Velocity liegt nicht über 42.»
- Power: Bei \(n = 9\) und einem Effekt von 2 SP: Power \(\approx 17\,\%\). Für 80 % Power wären ca. 47 Sprints nötig – der aktuelle Test ist stark underpowered.
- Fehler 2. Art: Das Team leistet tatsächlich über 42 SP/Sprint, der Test erkennt es nicht → ausbleibende Ressourcen oder fehlende Anerkennung.
Häufige Fehler: Zweiseitiger Test; Normalverteilung nicht geprüft; «nicht signifikant» = «kein Effekt».
Anm.: Der Shapiro-Wilk-Test auf Normalverteilung ist kein obligatorischer Test für das Modul WS!
TippLösung mit R anzeigen
Code
velocity <- c(38, 45, 47, 41, 50, 43, 39, 46, 44)
benchmark <- 42
# t-Test
ergebnis <- t.test(velocity, mu = benchmark,
alternative = "greater", conf.level = 0.95)
cat("x̄ =", round(mean(velocity), 4),
"| s =", round(sd(velocity), 4),
"| n =", length(velocity), "\n")x̄ = 43.6667 | s = 3.873 | n = 9 Code
cat("t =", round(ergebnis$statistic, 4), "\n")t = 1.291 Code
cat("df =", ergebnis$parameter, "\n")df = 8 Code
cat("p =", round(ergebnis$p.value, 4), "\n")p = 0.1164 Code
cat("95%-KI: [", round(ergebnis$conf.int[1], 3), "; +∞)\n\n")95%-KI: [ 41.266 ; +∞)Code
# Normalverteilungscheck
sw <- shapiro.test(velocity)
cat("Shapiro-Wilk: W =", round(sw$statistic, 4),
"| p =", round(sw$p.value, 4), "\n\n")Shapiro-Wilk: W = 0.9791 | p = 0.9594 Code
# Power-Analyse
pw <- power.t.test(n = 9, delta = 2, sd = sd(velocity),
sig.level = 0.05, type = "one.sample",
alternative = "one.sided")
n80 <- power.t.test(delta = 2, sd = sd(velocity),
sig.level = 0.05, power = 0.80,
type = "one.sample", alternative = "one.sided")
cat("Power bei n = 9, Effekt = 2 SP:", round(pw$power, 3), "\n")Power bei n = 9, Effekt = 2 SP: 0.41 Code
cat("Benötigtes n für 80 % Power: ≈", ceiling(n80$n), "Sprints\n")Benötigtes n für 80 % Power: ≈ 25 SprintsCode
# QQ-Plot
tibble(v = velocity) |>
ggplot(aes(sample = v)) +
stat_qq(color = "steelblue", size = 2.5) +
stat_qq_line(color = "grey40", linewidth = 0.7) +
labs(x = "Theoretische Quantile N(0,1)",
y = "Stichproben-Quantile",
title = "QQ-Plot: Sprint-Velocity (n = 9)") +
theme_minimal()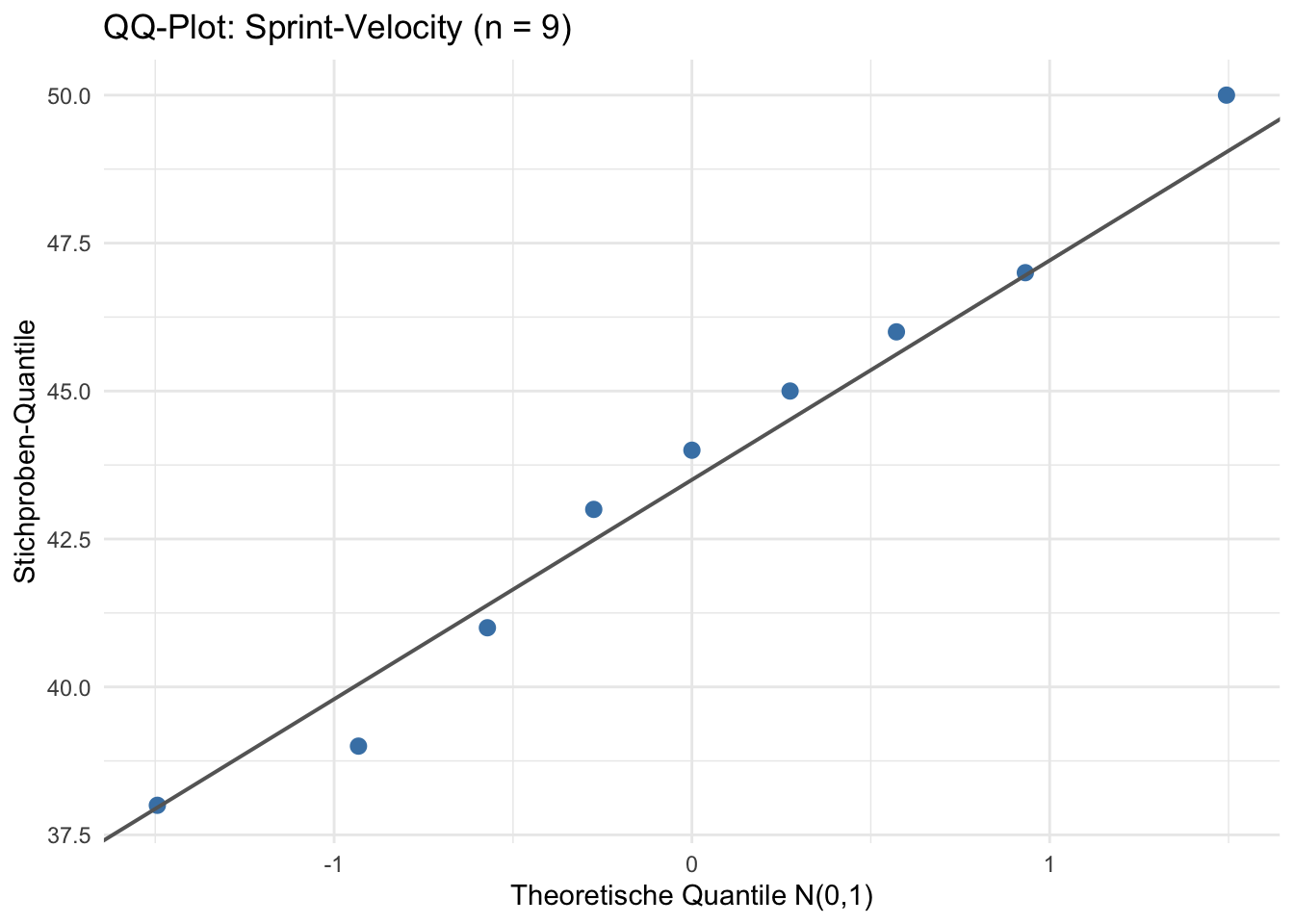
Aufgabe 4: Code-Review-Zeiten (verbundener t-Test)
Ein Softwareunternehmen führt ein KI-gestütztes Code-Review-Tool ein. Bei denselben 12 Entwickler:innen werden die mittleren Review-Zeiten (h) vor und nach der Einführung gemessen (Daten: code_review_zeiten.csv).
| Variable | Typ | Bedeutung |
|---|---|---|
entwickler |
kategorial | Kürzel der Entwickler:in (Dev_01 – Dev_12) |
vorher_h |
numerisch | Mittlere Review-Zeit vor Tool-Einführung (h) |
nachher_h |
numerisch | Mittlere Review-Zeit nach Tool-Einführung (h) |
Importieren Sie die Daten aus dem
code_review_zeiten.csv.Definieren Sie \(\mu_d = \mu_{\text{nachher}} - \mu_{\text{vorher}}\) und formulieren Sie \(H_0\) und \(H_1\). Begründen Sie die Testrichtung.
Warum ist der verbundene t-Test zwingend? Was verliert man, wenn man
paired = FALSEsetzt?
Berechnen Sie \(\bar{d}\) und \(s_d\) aus den Differenzen. Bestimmen Sie \(t = \bar{d} \,/\, (s_d/\sqrt{n})\) mit \(df = 11\). Kritischer Wert (linksseitig): \(t_{11;\,0{,}05} = -1{,}796\).
Führen Sie
t.test()mitpaired = TRUEund zum Vergleich mitpaired = FALSEdurch. Erklären Sie den Unterschied in den p-Werten.
Erläutern Sie: (1) Welche Varianzquelle wird durch die Differenzbildung eliminiert? (2) Schätzen Sie die wöchentliche Kapazitätswirkung bei 5 Reviews pro Person und Woche. (3) Warum wäre ein unverbundener Test hier methodisch falsch?
TippAnalytische Lösung anzeigen
a) Hypothesen
Das Tool soll die Review-Zeit verkürzen → \(\mu_d < 0\):
\[H_0: \mu_d \geq 0 \qquad \text{vs.} \qquad H_1: \mu_d < 0 \quad \text{(linksseitig)}\]
b) Paarstruktur
Dieselben 12 Personen werden zweimal gemessen → Paarstruktur vorhanden. Die Differenz \(d_i\) eliminiert individuelle Baseline-Unterschiede (Dev_6 ≈ 11 h vs. Dev_3 ≈ 5 h). Beim unverbundenen Test wird diese interindividuelle Streuung fälschlich als Fehler behandelt → grösserer Nenner im t-Bruch → kleineres \(|t|\) → grösserer p-Wert → niedrigere Power.
c) Analytische Berechnung
\[\bar{d} \approx -1{,}542\,\text{h}, \qquad s_d \approx 0{,}885\,\text{h}\]
\[t = \frac{-1{,}542}{0{,}885 \,/\, \sqrt{12}} = \frac{-1{,}542}{0{,}255} \approx -6{,}037, \qquad df = 11\]
Da \(-6{,}037 < -1{,}796\): \(H_0\) wird abgelehnt.
d) R-Ergebnis
Verbunden: \(p = 4{,}235 \cdot 10^{-5}\) (hochsignifikant). Unverbunden: \(p \approx 0{,}043\) (p-Wert ca. 1000-mal grösser).
e) Verständnis und Interpretation
- Varianzreduktion: Die Differenzen \(d_i\) haben eine Streuung von nur \(s_d \approx 0{,}885\) h. Die Rohdaten streuen zwischen Personen um mehrere Stunden – diese interindividuelle Varianz ist durch Differenzbildung eliminiert.
- Kapazitätswirkung: \(12 \times 5 \times 1{,}54 \approx 92{,}5\) Stunden/Woche gespart ≈ 2,3 Vollzeit-Arbeitstagen.
- Methodische Falschheit: Beim unverbundenen Test werden Personen mit hoher Baseline in «Vorher» und Personen mit niedriger Baseline in «Nachher» so behandelt, als wären sie zufällig verschiedene Personen – dabei sind es dieselben. Der Test misst dadurch die falsche Streuungsquelle.
Häufige Fehler: paired = FALSE trotz Paarstruktur; Differenz als Vorher − Nachher (statt umgekehrt); rechtsseitiger statt linksseitiger Test.
TippLösung mit R anzeigen
Code
review_daten <- read_csv("./data/code_review_zeiten.csv") |>
mutate(diff_vec = nachher_h - vorher_h)
cat("d̄ =", round(mean(review_daten$diff_vec), 4), "h\n")d̄ = -1.5417 hCode
cat("s_d =", round(sd(review_daten$diff_vec), 4), "h\n\n")s_d = 0.8847 hCode
# Verbundener t-Test (korrekt)
tv <- t.test(review_daten$nachher_h, review_daten$vorher_h,paired = TRUE, alternative = "less")
cat("Verbundener t-Test:\n")Verbundener t-Test:Code
cat(" t =", round(tv$statistic, 3),
"| df =", tv$parameter,
"| p =", round(tv$p.value, 6), "\n\n") t = -6.037 | df = 11 | p = 4.2e-05 Code
# Unverbundener t-Test (zum Vergleich)
tu <- t.test(review_daten$nachher_h, review_daten$vorher_h, paired = FALSE, alternative = "less")
cat("Unverbundener t-Test (Vergleich):\n")Unverbundener t-Test (Vergleich):Code
cat(" t =", round(tu$statistic, 3),
"| df =", round(tu$parameter, 1),
"| p =", round(tu$p.value, 4), "\n") t = -1.797 | df = 21.9 | p = 0.043 Aufgabe 5: Cloud-Anbieter im Latenz-Vergleich (Welch-t-Test)
Eine IT-Abteilung vergleicht zwei Cloud-Anbieter. Über je zwei unabhängige Wochen werden Latenzmessungen (ms) auf identischen VM-Instanztypen erhoben.
| Anbieter | n | Mittelwert (ms) | SD (ms) |
|---|---|---|---|
| A (EU-West) | 35 | 40.82 | 8.46 |
| B (EU-Central) | 38 | 42.04 | 8.33 |
Verwenden Sie \(\alpha = 0{,}05\).
- Formulieren Sie \(H_0\) und \(H_1\) mit \(\mu_A\) und \(\mu_B\). Begründen Sie den zweiseitigen Test.
- Sind die Messreihen verbunden oder unverbunden? Warum ist der Welch-Test (
var.equal = FALSE) dem klassischen t-Test vorzuziehen?
- Berechnen Sie \(t_W = (\bar{x}_A - \bar{x}_B) \,/\, \sqrt{s_A^2/n_A + s_B^2/n_B}\). Die Satterthwaite-Formel ergibt \(df \approx 67\); kritischer Wert: \(\pm t_{67;\,0{,}025} \approx \pm 1{,}996\).
- Führen Sie
t.test()mitvar.equal = FALSEdurch. Enthält das 95-%-KI für \(\mu_A - \mu_B\) den Wert 0?
- Erläutern Sie: (1) Was bedeutet es inhaltlich, wenn das 95-%-KI die Null enthält? (2) Was würde
var.equal = TRUEbei ungleichen Varianzen verfälschen? (3) Ist «nicht signifikant» dasselbe wie «kein Unterschied»?
TippAnalytische Lösung anzeigen
a) Hypothesen
Gefragt ist nach einem Unterschied, keine Richtung vorgegeben → zweiseitig:
\[H_0: \mu_A = \mu_B \qquad \text{vs.} \qquad H_1: \mu_A \neq \mu_B\]
b) Testwahl
Unverbunden: Die Messungen bei A und B haben keine natürliche Paarung. Welch-Test: \(s_A \approx 8\) ms vs. \(s_B \approx 11\) ms – sichtbar verschieden. var.equal = TRUE würde die Varianzen fälschlich zusammenlegen und zu falsch kalibrierten p-Werten führen.
c) Analytische Berechnung
Mit den Stichprobenwerten: \(\bar{x}_A \approx 40{,}97\), \(s_A \approx 7{,}97\), \(\bar{x}_B \approx 44{,}65\), \(s_B \approx 10{,}72\).
\[t_W = \frac{40{,}97 - 44{,}65}{\sqrt{7{,}97^2/35 + 10{,}72^2/38}} = \frac{-3{,}68}{\sqrt{4{,}84}} \approx -1{,}673\]
Da \(|-1{,}673| = 1{,}673 < 1{,}996\): \(H_0\) wird nicht abgelehnt.
d) R-Ergebnis
\(p \approx 0{,}099 > 0{,}05\). 95-%-KI \([-8{,}01;\, 0{,}66]\) ms enthält 0 → konsistent.
e) Verständnis und Interpretation
- KI enthält 0: Ein wahrer Unterschied von 0 ms ist mit den Daten verträglich. Das Intervall \([-8{,}0;\, 0{,}7]\) ms zeigt: Wir können keine sichere Aussage über die Richtung des Unterschieds machen.
- var.equal = TRUE: Beim klassischen t-Test wird ein gepoolter Schätzer für \(\sigma^2\) berechnet. Bei ungleichen Varianzen ist dieser verzerrt → zu kleiner oder zu grosser kritischer Wert → falsche Ablehnrate.
- Nicht signifikant ≠ kein Unterschied: Das Ergebnis zeigt nur, dass die Daten keinen ausreichenden Beleg für einen Unterschied liefern – insbesondere bei kleinen Stichproben könnte ein echter Unterschied unentdeckt bleiben.
Häufige Fehler: Einseitiger Test; paired = TRUE ohne Paarstruktur; var.equal = TRUE bei sichtbar verschiedenen SDs.
TippLösung mit R anzeigen
Code
set.seed(99)
anbieter_A <- round(rnorm(35, mean = 42, sd = 8), 1)
anbieter_B <- round(rnorm(38, mean = 46, sd = 11), 1)
ergebnis <- t.test(anbieter_A, anbieter_B,
alternative = "two.sided", var.equal = FALSE)
cat("x̄_A =", round(mean(anbieter_A), 2),
"ms | s_A =", round(sd(anbieter_A), 2), "ms\n")x̄_A = 40.82 ms | s_A = 8.46 msCode
cat("x̄_B =", round(mean(anbieter_B), 2),
"ms | s_B =", round(sd(anbieter_B), 2), "ms\n\n")x̄_B = 42.04 ms | s_B = 8.33 msCode
cat("Welch-t-Test:\n")Welch-t-Test:Code
cat(" t =", round(ergebnis$statistic, 4), "\n") t = -0.6225 Code
cat(" df =", round(ergebnis$parameter, 1), "(Satterthwaite)\n") df = 70.3 (Satterthwaite)Code
cat(" p =", round(ergebnis$p.value, 4), "\n") p = 0.5356 Code
cat(" 95%-KI: [", round(ergebnis$conf.int[1], 2), ";",
round(ergebnis$conf.int[2], 2), "] ms\n") 95%-KI: [ -5.15 ; 2.7 ] msAufgabe 6: Bug-Raten zweier Entwicklungsteams (Zweistichproben-Anteilstest)
Ein IT-Dienstleister vermutet einen Unterschied in der Bug-Rate zweier Entwicklungsteams. Im letzten Quartal lieferte Team Alpha 180 User Stories ab (27 mit kritischem Bug) und Team Beta 210 User Stories (22 mit kritischem Bug). Verwenden Sie \(\alpha = 0{,}05\).
- Formulieren Sie \(H_0\) und \(H_1\) mit \(p_\alpha\) und \(p_\beta\). Begründen Sie den zweiseitigen Test.
- Warum ist weder ein t-Test noch
binom.test()hier korrekt? Prüfen Sie die Faustregel \(n_i \hat{p}_i \geq 5\) für beide Gruppen.
- Berechnen Sie die gepoolte Schätzung \(\hat{p} = (x_\alpha + x_\beta) \,/\, (n_\alpha + n_\beta)\) und die Prüfstatistik \(\chi^2 = (\hat{p}_\alpha - \hat{p}_\beta)^2 \,/\, [\hat{p}(1-\hat{p})(1/n_\alpha + 1/n_\beta)]\). Kritischer Wert: \(\chi^2_{1;\,0{,}95} = 3{,}841\).
- Führen Sie
prop.test()durch. Berechnen Sie mitpower.prop.test()die benötigte Stichprobengrösse je Gruppe für 80 % Power.
- Erläutern Sie: (1) Was bedeutet «underpowered», und warum liefert «nicht signifikant» hier keinen Beweis für Gleichheit? (2) Was wäre ein Fehler 2. Art, und welche geschäftliche Folge könnte er haben? (3) Interpretieren Sie das 95-%-KI \((-2{,}0\,\%;\, +11{,}0\,\%)\) für \(p_\alpha - p_\beta\) inhaltlich.
TippAnalytische Lösung anzeigen
a) Hypothesen
Gefragt ist nach einem Unterschied, keine Richtung vorgegeben → zweiseitig:
\[H_0: p_\alpha = p_\beta \qquad \text{vs.} \qquad H_1: p_\alpha \neq p_\beta\]
b) Testwahl und Faustregel
Kein t-Test: Zielgrösse ist ein Anteil. Kein binom.test(): testet einen Anteil gegen einen Sollwert, nicht zwei gegen einander. Faustregel: \(180 \cdot 0{,}15 = 27 \geq 5\) ✓, \(180 \cdot 0{,}85 = 153 \geq 5\) ✓; ebenso für Beta → Normalapproximation zulässig.
c) Analytische Berechnung
\[\hat{p} = \frac{27 + 22}{180 + 210} = \frac{49}{390} \approx 0{,}1256\]
\[\chi^2 = \frac{(0{,}15 - 0{,}1048)^2}{0{,}1256 \cdot 0{,}8744 \cdot (1/180 + 1/210)} \approx \frac{0{,}002043}{0{,}001134} \approx 1{,}80\]
Da \(1{,}80 < 3{,}841\): \(H_0\) wird nicht abgelehnt.
d) R-Ergebnis
\(p \approx 0{,}179 > 0{,}05\). 95-%-KI \((-2{,}0\,\%;\, +11{,}0\,\%)\) enthält 0. Für 80 % Power: ≈ 560 User Stories je Gruppe nötig – mehr als dreimal so viel wie vorhanden.
e) Verständnis und Interpretation
- Underpowered: Die Power beträgt ca. 30 % – in 70 % der Fälle würde ein echter Unterschied von 4,5 Prozentpunkten übersehen. «Nicht signifikant» bedeutet hier primär «zu wenig Daten», nicht «kein Unterschied».
- Fehler 2. Art: Ein struktureller Qualitätsnachteil von Alpha bleibt unentdeckt → keine Massnahmen (bessere Testabdeckung, Code-Reviews) → Qualitätsunterschied persistiert.
- KI-Interpretation: Der wahre Unterschied \(p_\alpha - p_\beta\) liegt mit 95 % Wahrscheinlichkeit zwischen \(-2{,}0\,\%\) und \(+11{,}0\,\%\). Sowohl «kein Unterschied» als auch «Alpha 11 PP schlechter» sind mit den Daten verträglich – die Unsicherheit ist gross.
Häufige Fehler: t-Test auf Anteilen; binom.test() für zwei Gruppen; «nicht signifikant» = «kein Unterschied».
TippLösung mit R anzeigen
Code
x_vec <- c(27, 22)
n_vec <- c(180, 210)
# Zweistichproben-Anteilstest
ergebnis <- prop.test(x_vec, n_vec, alternative = "two.sided", correct = FALSE)
cat("p̂_Alpha =", round(x_vec[1]/n_vec[1]*100, 2), "%\n")p̂_Alpha = 15 %Code
cat("p̂_Beta =", round(x_vec[2]/n_vec[2]*100, 2), "%\n")p̂_Beta = 10.48 %Code
cat("χ² =", round(ergebnis$statistic, 4), "\n")χ² = 1.8056 Code
cat("p =", round(ergebnis$p.value, 4), "\n")p = 0.179 Code
cat("95%-KI (Alpha - Beta): [",
round(ergebnis$conf.int[1]*100, 2), "%; ",
round(ergebnis$conf.int[2]*100, 2), "%]\n\n", sep = "")95%-KI (Alpha - Beta): [-2.14%; 11.18%]Code
# Faustregel
p_hat <- x_vec / n_vec
for (i in 1:2) {
cat(c("Alpha", "Beta")[i], ": n*p̂ =",
round(n_vec[i]*p_hat[i], 1),
"| n*(1-p̂) =", round(n_vec[i]*(1-p_hat[i]), 1), "\n")
}Alpha : n*p̂ = 27 | n*(1-p̂) = 153
Beta : n*p̂ = 22 | n*(1-p̂) = 188 Code
# Power-Analyse
n_pwr <- power.prop.test(p1 = 0.15, p2 = 0.105,
sig.level = 0.05, power = 0.80)
cat("\nBenötigtes n je Gruppe (80 % Power): ≈", ceiling(n_pwr$n), "\n")
Benötigtes n je Gruppe (80 % Power): ≈ 862 Bonus: Fehleranalyse
WichtigAufgabe
Der folgende Text enthält drei Fehler: einen in der Hypothesenformulierung, einen bei der Testwahl und einen bei der p-Wert-Interpretation. Benennen Sie alle drei Fehler präzise, erklären Sie warum sie falsch sind, und formulieren Sie die korrekte Version.
«Ein DevOps-Team prüft, ob die neue Monitoring-Plattform die mittlere Incident-Erkennungszeit von 8,5 Minuten verändert hat. Nach dem Rollout werden 25 Incidents gemessen. Hypothesen: \(H_0: \mu \neq 8{,}5\) vs. \(H_1: \mu = 8{,}5\). Durchführung: binom.test(x = mean(incidents), n = 25, p = 0.5, alternative = "two.sided"). Ergebnis: \(p = 0{,}03\). Schlussfolgerung: Die Erkennungszeit beträgt nun mit 97-%-Wahrscheinlichkeit exakt 8,5 Minuten.»
TippLösung anzeigen
Fehler 1 – Hypothesen vertauscht
\(H_0\) und \(H_1\) sind vertauscht. \(H_0\) ist immer die «kein Effekt»-Hypothese.
Korrekt: \(H_0: \mu = 8{,}5\,\text{min}\) vs. \(H_1: \mu \neq 8{,}5\,\text{min}\) (zweiseitig)
Fehler 2 – Falsche Testfunktion
binom.test() testet eine Bernoulli-Erfolgswahrscheinlichkeit (Anteil). Die Erkennungszeit ist eine metrische Variable.
Korrekt: t.test(incidents, mu = 8.5, alternative = "two.sided")
Fehler 3 – p-Wert falsch interpretiert
«97-%-Wahrscheinlichkeit, dass \(\mu = 8{,}5\)» ist eine klassische Fehlinterpretation.
Korrekte Interpretation: Falls \(H_0\) wahr wäre, würde ein so extremes Ergebnis mit Wahrscheinlichkeit \(p = 0{,}03\) auftreten. Da \(p < 0{,}05\), wird \(H_0\) abgelehnt – es besteht statistisch signifikante Evidenz für eine Veränderung der Erkennungszeit.
HinweisWeiterführende Literatur
- Mittag, H.-J. & Schüller, K. (2023). Statistik. Springer Gabler. Kapitel 16.
- Wasserstein, R. L. & Lazar, N. A. (2016). The ASA’s statement on p-values. The American Statistician, 70(2), 129–133.
- Cohen, J. (1994). The earth is round (p < .05). American Psychologist, 49(12), 997–1003.